Stephen LaPorte
Shared posts
Where in the USA is this?
10 Typos
Stephen LaPorteI love this trend of simple daily games.
22 years of Wikipedia
I was just reading a long discussion regarding the differences between Open Street Maps and Wikipedia / Wikidata, and one of the mappers complained "Wiki* cares less about accuracy than the fact that there is something that can be cited", and calling Wikipedia / Wikidata contributions "armchair work" because we don't go out into the world to check a fact, but rely on references.
I understand the expressed frustration, but at the same time I'm having a hard time letting go of "reliability not truth" being a pillar of Wikipedia.
But this makes Wikipedia an inherently conservative project, because we don't reflect a change in the world or in our perception directly, but have to wait for reliable sources to put it in the record. There's something I was deeply uncomfortable with: so much of my life is devoted to a conservative project?
Wikipedia is a conservative project, but at the same time it's a revolutionary project. Making knowledge free and making knowledge production participatory is politically and socially a revolutionary act. How can this seeming contradiction be brought to a higher level of synthesis?
In the last few years, my discomfort with the idea of Wikipedia being conservative has considerably dissipated. One might think, sure, that happened because I'm getting older, and as we get older, we get more conservative (there's, by the way, unfortunate data questioning this premise: maybe the conservative ones simply live longer because of inequalities). Maybe. But I like to think that the meaning of the word "conservative" has changed. When I was young, the word conservative referred to right wing politicians who aimed to preserve the values and institutions of their days. An increasingly influential part of todays right wing though has turned into a movement that does not conserve and preserve values such as democracy, the environment, equality, freedoms, the scientific method. This is why I'm more comfortable with Wikipedia's conservative aspects than I used to be.
But at the same time, that can lead to a problematic stasis. We need to acknowledge that the sources and references Wikipedia has been built on, are biased due to historic and ongoing inequalities in the world, due to different values regarding the importance of certain types of references in the world. If we truly believe that Wikipedia aims to provide everyone with access to the sum of all human knowledge, we have to continue the conversations that have started about oral histories, about traditional knowledges, beyond the confines of academic publications. We have to continue and put this conversation and evolution further into the center of the movement.
Happy Birthday, Wikipedia! 22 years, while I'm 44 - half of my life (although I haven't joined until two years later). For an entire generation the world has always been a world with free knowledge that everyone can contribute to. I hope there is no going back from that achievement. But just as democracy and freedom, this is not a value that is automatically part of our world. It is a vision that has to be lived, that has to be defended, that has to be rediscovered and regained again and again, refined and redefined. We (the collective we) must wrest it from the gatekeepers of the past (including me) to allow it to remain a living, breathing, evolving, ever changing project, in order to not see only another twenty two years, but for us to understand this project as merely a foundation that will accompany us for centuries.
| Previous entry: Good bye, kuna! |
Next entry: Connectionism and symbolism: The fall of the symbolists |
Wikidata - The Game
Wikipedia’s new look makes it easier to use for everyone
Stephen LaPorteWikipedia's new look: with a sticky ToU, cleaner menu, plus more prominent search bar and language-switch interface.
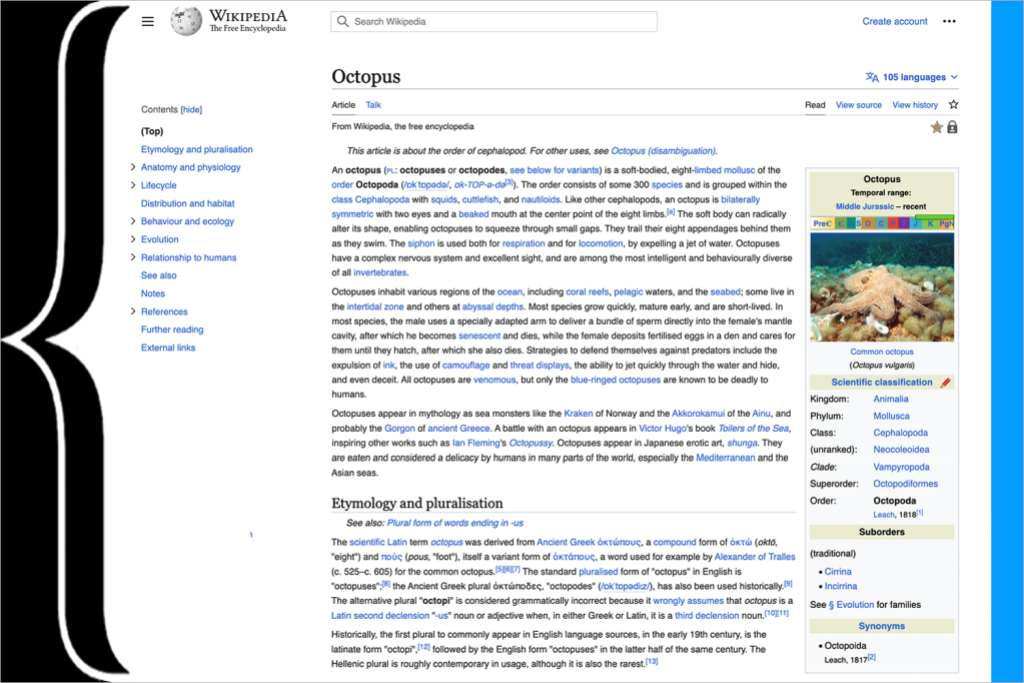
Discover the journey behind Wikipedia’s new look on Diff.
If you are a reader of Wikipedia on desktop, you might have noticed something new over the past couple of days. The website looks a bit different — it’s simpler; less cluttered; and, hopefully, easier to use. After three years of development, the Wikimedia Foundation has finally released the updated desktop interface for Wikipedia. The new look went live today on English Wikipedia, during the month of its 22nd birthday, and is currently live on over 300 language editions of Wikipedia.
The result of the Desktop Improvements Project, the new look was built with the objective of making our interfaces more welcoming for readers globally, and more useful for new and advanced users across Wikimedia projects. The new design is the culmination of years of research, dozens of consultations with movement groups and volunteers, and thousands of points of feedback from Wikipedia readers.
The updated interface improves readability by reducing distraction and clutter and making pages easier to read. It introduces changes to the navigation and layout of the site, adds persistent elements such as a sticky header (a header that moves with you as you scroll) and Table of Contents to make frequently-used actions easier to access, and makes some changes to the overall styling of the page. Our data shows that these changes improve usability, and save time currently spent in scrolling, searching, and navigating – all of which adds up to an easier and more modern reading experience, so that more people will love reading and contributing to Wikipedia.
We are extremely excited for this change and that new audiences will be able to use the desktop site more comfortably. The previous interface, named Vector, had been in use since 2010. When it was developed, it reflected the needs of the readers and editors of the Wikimedia sites at the time. Since then, vast new audiences from a wide variety of cultural backgrounds have begun using the Internet and Wikimedia projects, and our research showed that we were not meeting their needs fully.
The Vector 2022 interface aims to make changes that include the needs of all audiences – both those who have been using the projects for a long time, as well as those who have joined more recently, or have yet to join. We encourage you to read our blog post on equitable product development to gain more insight into the way we identified the needs and included the voices of our large set of audiences into the product development process.
The interface was built and tested in collaboration with different audiences and communities across our projects, and inspired by the ideas and efforts that volunteers had worked on and created over the years. We were lucky to partner with many different language communities, such as French Wikipedia, Korean Wikipedia, Persian Wikipedia, and many more, who tested the interface and new features from its conception and gave us their insights, concerns, and questions, so that we could improve and build based on what our readers and communities truly needed.
In the future, we plan on continuing to listen to our audiences and adapt and improve our experiences based on their needs. In many ways, we see this as a new chapter in the development of our desktop site, a beginning marked with a clean slate on which a wide variety of new features can be built, rather than a static interface we will change once again in a decade. We are excited for these changes, and the opportunities they give us in the future to better serve our audiences. And most of all, we are excited to welcome you to the new experience.
To learn more about the updated desktop interface, see the FAQ. You can also share feedback at this link.
Dear Supreme Court: Judicial Curtailing Of Section 230 Will Make The Internet Worse
Every amicus brief the Copia Institute has filed has been important. But the brief filed today is one where all the marbles are at stake. Up before the Supreme Court is Gonzalez v. Google, a case that puts Section 230 squarely in the sights of the Court, including its justices who have previously expressed serious misunderstandings about the operation and merit of the law.
As we wrote in this brief, the Internet depends on Section 230 remaining the intentionally broad law it was drafted to be, applying to all sorts of platforms and services that make the Internet work. On this brief the Copia Institute was joined by Engine Advocacy, speaking on behalf of the startup community, which depends on Section 230 to build companies able to provide online services, and Chris Riley, an individual person running a Mastodon server who most definitely needs Section 230 to make it possible for him to provide that Twitter alternative to other people. There seems to be this pervasive misconception that the Internet begins and ends with the platforms and services provided by “big tech” companies like Google. In reality, the provision of platform services is a profoundly human endeavor that needs protecting in order to be sustained, and we wrote this brief to highlight how personal Section 230’s protection really is.
Because ultimately without Section 230 every provider would be in jeopardy every time they helped facilitate online speech and every time they moderated it, even though both activities are what the Internet-using public needs platforms and services to do, even though they are what Congress intended to encourage platforms and services to do, and even though the First Amendment gives them the right to do them. Section 230 is what makes it possible at a practical level for them to them by taking away the risk of liability arising from how they do.
This case risks curtailing that critical statutory protection by inventing the notion pressed by the plaintiffs that if a platform uses an algorithmic tool to serve curated content, it somehow amounts to having created that content, which would put the activity beyond the protection of Section 230 as it only applies to when platforms intermediate content created by others and not content created by themselves. But this argument reflects a dubious read of the statute, and one that would largely obviate Section 230’s protection altogether by allowing liability to accrue as a result of some quality in the content created by another, which is exactly what Section 230 is designed to forestall. As we explained to the Court in detail, the idea that algorithmic serving of third party content could somehow void a platform’s Section 230 protection is an argument that had been cogently rejected by the Second Circuit and should similarly be rejected here.
Oral argument is scheduled for February 21. While it is possible that the Supreme Court could take onboard all the arguments being brought by Google and the constellation of amici supporting its position, and then articulate a clear defense of Section 230 platform operators could take back to any other court questioning in their statutory protection, it would be a good result if the Supreme Court simply rejected this particular theory pressing for artificial limits to Section 230 that are not in the statute or supported by the facially obvious policy values Section 230 was supposed to advance. Just so long as the Internet and the platforms that make up it can live on to fight another day we can call it a win. Because a decision in favor of the plaintiffs curtailing Section 230 would be an enormous loss to anyone depending on the Internet to provide them any sort of benefit. Or, in other words, everyone.
Chronophoto
2023, and welcome new subscribers
Stephen LaPorteInteresting reflections on Wikipedia's discussion of ChatGPT.

So I have 30% more subscribers now than I did when I did the last newsletter, which is fun! Welcome to all the new folks. A few things to note/know:
- Beginner’s mind: I’m trying very hard to approach AI with humility—and encourage everyone from “traditional” open to do the same. That’s particularly relevant this week because I’m seeing lots of AI-space writers start the year with 2023 predictions, and I won’t be doing that—there’s still too much I don’t know. (My long-term prediction, though, is here. tldr: as big as the printing press?)
- Open(ish): If you’re new here, you might want to read my essay on open(ish)—where I talk about what traditional open has meant to me and what of that might (or might not) transfer to what I’ve been calling open(ish) machine learning. The most important thing to know is that I find the question “is some-ML-thing OSI-open” to be a nearly completely-uninteresting question.
- Ghost: I use Ghost (an AGPL newsletter/blog tool), but TBH my experience with it has been mediocre so that’ll probably only until I can find the time to switch. So please forgive me if some time in the next few weeks you get a re-subscribe request from another platform.
Smaller, Better, Cheaper, Faster
One of the things that prompted me to start writing this was the change in what tech we thought was necessary to do ML. Two recent notes on that front:
- "Cramming": A paper on training a language model on a single GPU in a single day, and a good Twitter summary of the paper. Results: can reach 2018 state-of-the-art this way. 2018 state of the art is no longer great, and there are reasons to think there are natural limits to this approach, but doing it in one day on one card represents massive progress—especially since they do not enable most hardware speedups, so these wins are mostly because of more efficient techniques and software.
- NanoGPT: Where the previous example used a lot of complexity to save on training time, this MIT-licensed repo goes the other way: training a medium-size language model in a mere 300 lines of code. Like many “small”, “simple” tools, of course, much of the simplicity is because underlying tools (here, PyTorch) provide a lot of power.
I think it’s safe to say that we’re going to continue to see both announcements about high-end training becoming very high-end (vast numbers of expensive GPUs, running continuously) but also increased experimentation at the low end.
Should you use ML tools?
In this newsletter, so far, I've focused less on what “should” happen and more on what the possibilities are: is meaningfully open ML feasible? What would that mean? What impact would that have? Two recent good pieces do touch on that "should" question:
- Friend-of-the-newsletter Sumana has a succinct, practical summary of “should” questions in a post on her use of Whisper, an openly-licensed speech-to-text model. I particularly like Sumana’s use of “reverence” to describe her respect for artists—and her admission that gut feel is a factor (here, in favor of transcription but perhaps against use in art).
- This essay on “ChatGPT should not exist” is more acute than most, getting to the root of a critical question: what does this tooling mean for our humanity? I think ultimately I disagree with the author's conclusion, because I think tool-using is (or at least can be) a critical part of what it means to be human. But I respect the question, and think we'll all have to grapple with real modern Luddism (in the most serious, thoughtful sense of that word) soon.
Wikipedia and ChatGPT
Wikipedia has been having some conversations about ChatGPT (mailing list, English Wikipedia chat). A few observations:
Wikipedia is not as central to ML as it was
5-7 years ago, ML techniques relied heavily on well-structured data like Wikipedia. That’s no longer the case, because the techniques for dealing with unstructured data have become much better, and the volume of training data used has gone way up.
One publicly-documented ML data project—The Pile—can give us a sense of the state of the art. In early 2021, Wikipedia was already a small component:
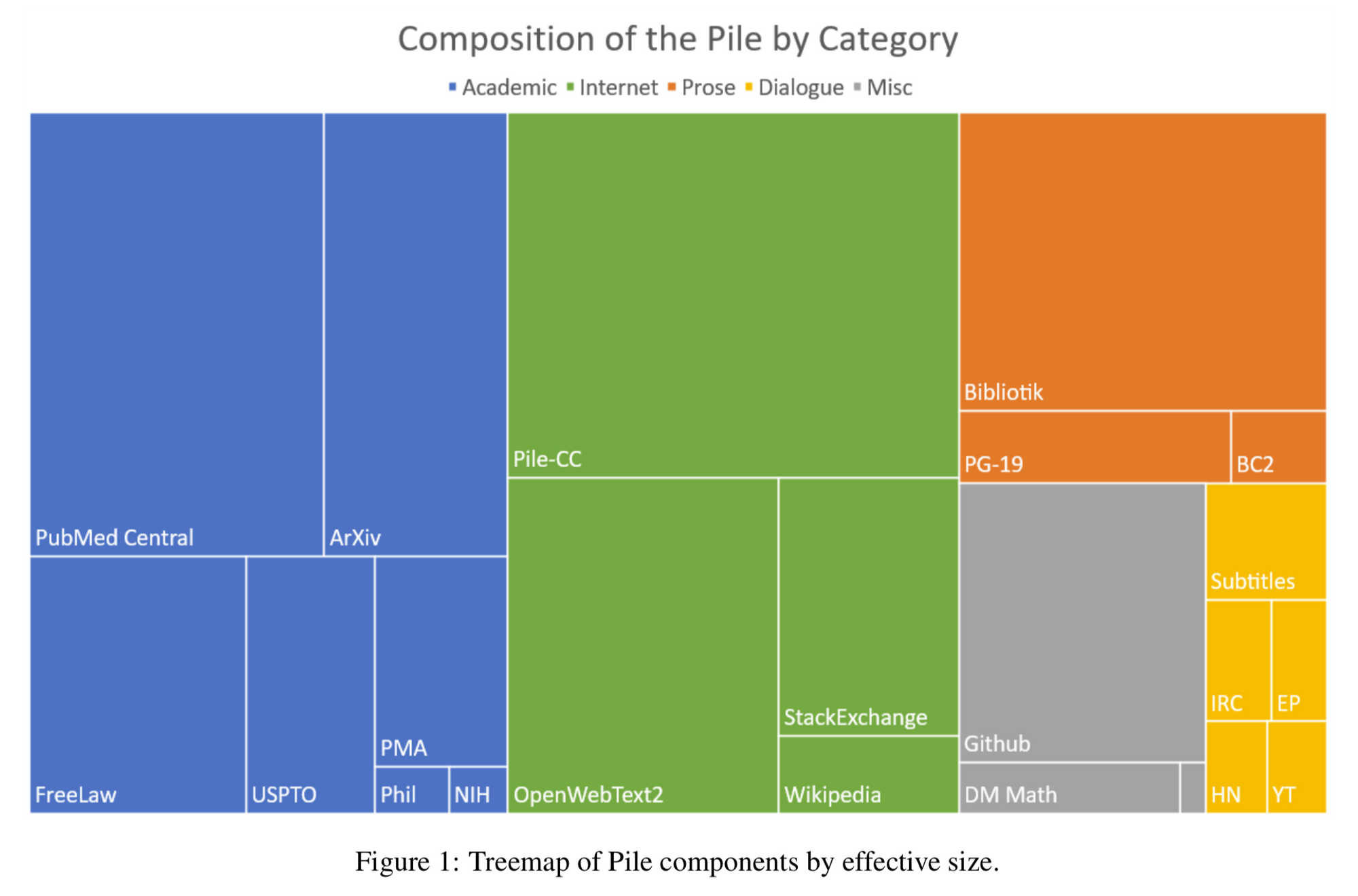
I’ve seen similar numbers in other recent papers. That’s not to say Wikipedia isn’t important (eg this 2022 paper from Facebook relies on it quite heavily), but it’s not essential as it once was, so it now approaches the problem with less leverage than it had even a few years ago.
Good enough?
One discussant pointed out that Wikipedia “thrived because our readers find us ‘good enough’”. This is critical! It’s an easy and common mistake to measure machine learning only against the best of humanity and humanity’s outputs—to understand where ML will have impact, it also has to be compared against mediocre and bad human outputs. (Early Wikipedia, as a reminder, was very bad!) Wikipedia has a better chance than most victims of the innovator's dilemma to collaborate with the new tools—we'll see if that actually happens in practice or not.
Trust shortage as opportunity?
Early Wikipedia benefited a lot from the shortage of simple, credible, fact-centric text on the early internet. It seems likely that soon we'll have a glut of text, while having an even greater shortage of trustworthy text. If Wikipedia can cross that gap, it could be potentially even more influential than it already is.
Creative Commons
I’ve mentioned before that Creative Commons is investigating machine learning, and Creative Common’s most famous user—Wikipedia—is going to be where that rubber meets the road. I don't anticipate a CC5, but it wouldn't surprise me to see a joint announcement of some sort.
An under-appreciated fact about Creative Commons is that it was the first open license, to the best of my knowledge, to explicitly endorse fair use—something since adopted by GPL v3, MPL v2, and other open licenses. In some sense, this is redundant—a license, by definition, can’t take away your fair use rights. But it’s still an important reminder when asking “what does Wikipedia’s license allow” that CC endorses a world where licenses are not all-powerful.
Self-fact-checking?
In the discussion, one Wikimedian claimed that “AI simply can’t discriminate between good research and bad research”. I think that’s probably correct—with two important caveats.
First, humans aren’t actually that good at this problem either—here’s a great article on the shortcomings of peer review. Wikipedia also once happily ingested all of the 1913 Encyclopedia Brittanica, whose commitment to "good research" would be disputed by women, Africans, Asians, etc.
Second, there’s interesting research going on on how to marry LLMs with reliable datasets to reduce “hallucination”. (Google paper, Facebook paper) I’d expect we’ll see a lot more creativity in this area soon, because Wikipedians aren’t the only ones who want more reliability. Wikipedia can engage with this, or (likely) get steamrolled by it.
Misc.
- Stable Diffusion posted a (half)year-in-review thread that’s pretty wild. SD is not traditionally open, but the velocity and variety of deployment and use are verrrry reminiscent of the path of early “real” open techs like Linux, Apache, and MySQL.
- Algorithmic power: In talking about ML regulation recently, it’s been very useful for me to revisit Lessig’s “modalities of regulation”. In this talk by Seth Lazar (notes) he expands on Lessig's “code is law” by going deep on algorithms as power. Given that part of what’s important about “open” is its impact on power, this will be something I'd like to explore more.
- Legal training data? By the nature of the profession, legal data sets for ML training are hard to get at. I was pointed at this one recently, so sharing here, but it’s quite small. I have to wonder if, ironically, ML will be good only at the stuff we do “for fun” because that’s, primarily, what’s on the internet—boring professional work may be more difficult for ML because good data will be harder to find.
- Professional exams: Very related to professional data sets: can GPT pass the bar exam? Not yet. Can it pass medical exams? Not yet. I suspect this particular problem may look a lot like the self-driving car: getting 80% of the way there is doable, but getting further is going to be very hard, in part because of data and in part because of the nuance necessary for professions. But that doesn’t mean they won’t be very useful tools—and potentially replace some specific use-cases—but they won't replace general-purpose lawyers or doctors for a while.
- New art from long-dead artists I’m enchanted by this use of generative ML to re-imagine/extend the career of an artist who died young, 170+ years ago.
- What professors did on their holiday break: I’m seeing many, many examples of professors who spent the break playing with ChatGPT and, in the new semester, experimenting with how to incorporate chatbots into their teaching. One example, of many.
And on a joyful note…
This README is good nerd humor:
My functions were written by humans. … How can I make them more dangerously unpredictable?
Using AI to make arrays of data infinitely long. By filling them with what, you may ask? (The answer, of course, is … filling them with AI! So slow, and probably garbage, and… nevertheless a fun, hopefully harmless, thought experiment…)
The 25 Best Films of 2022
It’s here, it’s here! David Erhlich’s annual 25 best films of the year video for 2022 is here. Every year around this time, I get a little down about the movies. There’s nothing to seeeeee… And then I watch Erhlich’s 17-minute love letter to cinema and I want to see ever-ry-thing. The only complaint I have is that Everything Everywhere All at Once is not rated highly enough (a respectable #3 but not #1).
Erhlich has been doing these recaps since 2012 — you can find them all here or almost all of them at kottke.org with my commentary.
Tags: best of best of 2022 David Ehrlich lists moviesHollywood Lobbyists Intervene Against Proposal to Share Vaccine Technology
Many industries across the U.S. have expressed alarm over the proposed waiver, which was put forth by a coalition of over 100 countries, led by India and South Africa, and would waive intellectual property rules in order to boost production of vaccines, medical products, and research toward ending the Covid-19 pandemic.
This might seem irrelevant to Hollywood, major publishing companies, and the music industry, but recently released disclosures show that these sectors have mobilized lobbyists to raise concerns with the waiver proposal.
The Motion Picture Association, which represents major movie and television studios, deployed five lobbyists to influence Congress and the White House over the waiver. The Association of American Publishers as well as Universal Music have similarly revealed that they are actively lobbying against it.
The Tyranny of Stuctureless
Stephen LaPorteI think about the "star system" backlash a lot.
Stephen LaPorteIt's been so long, I can't remember... what did Google Reader have that The Old Reader doesn't?
THROAT NOTES
https://www.patreon.com/felixcolgrave/
Finland adds demoscene to National Inventory of Living Heritage
Stephen LaPorteThere was an old campaign to make wikipedia a heritage site!
The Legality of Interstate Compacts
Stephen LaPorteThis is my favorite way to learn about the constitution.
"No State shall, without the Consent of Congress . . . enter into any Agreement or Compact with another State, or with a foreign Power, or engage in War, unless actually invaded, or in such imminent Danger as will not admit of delay."
Two groups of states (all with Democratic Governors) have reached agreements amongst themselves to coordinate their plans to reopen their economies when appropriate. Presumably they are doing this because they do not trust the Federal Government (in other words, the Trump Administration) to give them coherent advice. But can these states make these plans without the consent of Congress?
One way to think about this issue is by parsing the text that I just quoted. What is an agreement or compact exactly? Are certain formalities required or is any understanding between or among states (however informal) enough? Does the qualification about invasion or imminent danger apply only to fighting wars, or also to the earlier part about an interstate agreement or compact? If the qualification does apply, are decisions about how to reopen state economies a matter of imminent danger?
Another way to look at this problem is that nobody has standing to challenge these interstate arrangements. There could be circumstances where an individual or a state would be harmed by an interstate agreement reached without congressional consent, but I'm hard-pressed to see who would be in this instance.
The final, and most likely solution, is that nobody will pay attention to the issue at all because a state of emergency exists.
Patent holders urged to take “Open COVID Pledge” for quicker end to pandemic
Stephen LaPorteNot a fan of the Open COVID License they threw into the mix, but I'm glad they are putting the intention out there. It would be great if Gates or CZI were on board!
We Need A Massive Surveillance Program
Stephen LaPorteI'm surprised, this is a corner where I didn't expect to see a willingness to cede so much on privacy. In a country where we're struggling to do basics like timely testing, this whole position is uncharacteristically techno utopiast.
I am a privacy activist who has been riding a variety of high horses about the dangers of permanent, ubiquitous data collection since 2012.
But warning people about these dangers today is like being concerned about black mold growing in the basement when the house is on fire. Yes, in the long run the elevated humidity poses a structural risk that may make the house uninhabitable, or at least a place no one wants to live. But right now, the house is on fire. We need to pour water on it.
In our case, the fire is the global pandemic and the severe economic crisis it has precipitated. Once the initial shock wears off, we can expect this to be followed by a political crisis, in which our society will fracture along pre-existing lines of contention.
But for the moment, we are united by fear and have some latitude to act.
Doctors tell us that if we do nothing, the coronavirus will infect a large fraction of humanity over the next few months. As it spreads, the small proportion of severe cases will overwhelm the medical system, a process we are seeing play out right now in places like Lombardy and New York City. It is imperative that we slow this process down (the famous 'flattening the curve') so that the peak of infections never exceeds our capacity to treat the severely ill. In the short term this can only be done by shutting down large sections of the economy, an unprecedented move.
But once the initial outbreak is contained, we will face a dilemma. Do we hurt people by allowing the economy to collapse entirely, or do we hurt people by letting the virus spread again? How do we reconcile the two?
One way out of the dilemma would be some kind of medical advance—a vaccine, or an effective antiviral treatment that lowered the burden on hospitals. But it is not clear how long the research programs searching for these breakthroughs will take, or whether they will succeed at all.
Without these medical advances, we know the virus will resume its spread as soon as the harsh controls are lifted.
Doctors and epidemiologists caution us that the only way to go back to some semblance of normality after the initial outbreak has been brought under control will be to move from population-wide measures (like closing schools and making everyone stay home) to an aggressive case-by-case approach that involves a combination of extensive testing, rapid response, and containing clusters of infection as soon as they are found, before they have a chance to spread.
That kind of case tracking has traditionally been very labor intensive. But we could automate large parts of it with the technical infrastructure of the surveillance economy. It would not take a great deal to turn the ubiquitous tracking tools that follow us around online into a sophisticated public health alert system.
Every one of us now carries a mobile tracking device that leaves a permanent trail of location data. This data is individually identifiable, precise to within a few meters, and is harvested by a remarkable variety of devices and corporations, including the large tech companies, internet service providers, handset manufacturers, mobile companies, retail stores, and in one infamous case, public trash cans on a London street.
Anyone who has this data can retroactively reconstruct the movements of a person of interest, and track who they have been in proximity to over the past several days. Such a data set, combined with aggressive testing, offers the potential to trace entire chains of transmission in real time, and give early warning to those at highest risk.
This surveillance sounds like dystopian fantasy, but it exists today, ready for use. All of the necessary data is being collected and stored already. The only thing missing is a collective effort to pool it and make it available to public health authorities, along with a mechanism to bypass the few Federal privacy laws that prevent the government from looking at the kind of data the private sector can collect without restraint.
We've already seen such an ad-hoc redeployment of surveillance networks in Israel, where an existing domestic intelligence network was used to notify people that they had possibly been infected, and should self-quarantine, a message that was delivered by text message with no prior warning that such a system even existed.
We could make similar quick changes to the surveillance infrastructure in the United States (hopefully with a little more public awareness that such a system was coming online). When people are found to be sick, their location and contact history could then be walked back to create a list of those they were in touch with during the period of infectiousness. Those people would then be notified of the need to self-quarantine (or hunted with blowguns and tranquilizer darts, sent to FEMA labor camps, or whatever the effective intervention turns out to be.)
This tracking infrastructure could also be used to enforced self-quarantine, using the same location-aware devices. The possibilities of such a system are many, even before you start writing custom apps for it, and there would be no shortage of tech volunteers to make it a reality.
The aggregate data set this surveillance project would generate would have enormous value in its own right. It would give public health authorities a way to identify hot spots, run experiments, and find interventions that offered the maximum benefit at the lowest social cost. They could use real-time data and projections to allocate scarce resources to hospitals, and give advance warnings of larger outbreaks to state and Federal authorities in time to inform policy decisions.
Of course, all of this would come at an enormous cost to our privacy. This is usually the point in an essay where I’d break out the old Ben Franklin quote: “those who would give up essential liberty to purchase a little temporary safety deserve neither.”
But this proposal doesn’t require us to give up any liberty that we didn't already sacrifice long ago, on the altar of convenience. The terrifying surveillance infrastructure this project requires exists and is maintained in good working order in the hands of private industry, where it is entirely unregulated and is currently being used to try to sell people skin cream. Why not use it to save lives?
The most troubling change this project entails is giving access to sensitive location data across the entire population to a government agency. Of course that is scary, especially given the track record of the Trump administration. The data collection would also need to be coercive (that is, no one should be able to opt out of it, short of refusing to carry a cell phone). As with any government surveillance program, there would be the danger of a ratchet effect, where what is intended as an emergency measure becomes the permanent state of affairs, like happened in the United States in the wake of the 2001 terrorist attacks.
But the public health potential of commandeering surveillance advertising is so great that we can’t dismiss it out of hand. I am a privacy activist, typing this through gritted teeth, but I am also a human being like you, watching a global calamity unfold around us. What is the point of building this surveillance architecture if we can't use it to save lives in a scary emergency like this one?
One existing effort we could look to as a model for navigating this situation is the public/private partnership we have set up to monitor child sexual abuse material (CSAM) on the Internet.
Large image sharing sites like Facebook, Google, and Snapchat use a technology called PhotoDNA to fingerprint and identify images of known abuse material. They do this voluntarily, but if they find something, they are required by law to report it to the National Center for Missing and Exploited Children, a nongovernmental entity that makes referrals as appropriate to the FBI.
The system is not perfect, and right now is being used as a political football in a Trump administration attempt to curtail end-to-end encryption. But it shows the kind of public-private partnership you can duct tape together when the stakes are high and every party involved feels the moral imperative to act.
In this spirit, I believe the major players in the online tracking space should team up with the CDC, FEMA, or some other Federal agency that has a narrow remit around public health, and build a national tracking database that will operate for some fixed amount of time, with the sole purpose of containing the coronavirus epidemic. It will be necessary to pass legislation to loosen medical privacy laws and indemnify participating companies from privacy lawsuits, as well as override California's privacy law, to collect this data I don’t believe the legal obstacles are insuperable, but I welcome correction on this point by people who know the relevant law.
This enabling legislation, however, should come at a price. We have an opportunity to lay a foundation for the world we want to live in after the crisis is over. One reason we tolerate the fire department knocking down our door when there is an emergency is that we have strong protections against such intrusions, whether by government agencies or private persons, in more normal times. Those protections don't exist right now for online privacy. One reason this proposal is so easy to float is that private companies have enjoyed an outrageous freedom to track every aspect of our lives, keeping the data in perpetuity, and have made full use of it, turning the online economy into an extractive industry. That has to end.
Including privacy guarantees in the enabling legislation for public health surveillance will also help ensure that emergency measures don't become the new normal. If we use this capability deftly, we could come out of this crisis with a relatively intact economy, a low cumulative death toll, and a much healthier online sphere.
Of course, the worst people are in power right now, and the chances of them putting such a program through in any acceptable form are low. But it’s 2020. Weirder things have happened. The alternative is to keep this surveillance infrastructure in place to sell soap and political ads, but refuse to bring it to bear in a situation where it can save millions of lives. That would be a shameful, disgraceful legacy indeed.
I continue to believe that living in a surveillance society is incompatible in the long term with liberty. But a prerequisite of liberty is physical safety. If temporarily conscripting surveillance capitalism as a public health measure offers us a way out of this crisis, then we should take it, and make full use of it. At the same time, we should reflect on why such a powerful surveillance tool was instantly at hand in this crisis, and what its continuing existence means for our long-term future as a free people.
The Ferguson Principles
Thank you for the opportunity to speak with you today here in Wellington. It really is a privilege to be here. For the next few minutes I’m going to be talking about the efforts of the Documenting the Now project to build a community of practice around social media archiving. For Lave & Wenger (1991) a community of practice is a way of understanding how groups of people learn, by sharing skills and tools in relationship with each other, and in their daily lived experience. I think the best of what IIPC has to offer is as a community of practice.
But before I tell you about DocNow I need to do a little framing. Please forgive me if this seems redundant or obvious. I’ve been interested in web archiving for close to 10 years, but this is my first time here at the Web Archiving Conference.
A significant part of our work in Documenting the Now has been appreciating, and coming to terms with, the scale of the web. As you know the work of archiving social media is intrinsically bound up with archiving the web. But archiving the web is a project whose scale is paradoxically both much bigger, and much, much smaller, than the IIPC and its member institutions.

So I said it is a privilege to be here, and I meant it. According to the Carbon Footprint Calculator my return trip from Washington DC amounts to 2.19 metric tons of CO₂. To put this in perspective the Environmental Defense Fund estimates that the average American car emits about 7 tons of CO₂ in a year. How many cars do you think our conference amounts to? Hopefully you’ll see why this is important in a moment.
Bigger
Perhaps you saw this story in the Guardian about the projected energy consumption of the Internet? According to the piece, researchers estimate that by 2020 running the Internet will generate 3.5% of all global emissions, which will exceed that of the entire aviation and shipping industries. That’s only a year away.

By 2025 the Internet and all its connected devices could use up to 20% of the world’s electricity. By 2040 Internet carbon emissions will be up to 14%, which is roughly the same amount as the entire United States today. Even if 100% of future data centers use renewable energy sources the additional demand for electricity would significantly eat into any savings that would have made in overall energy use.
We have a tsunami of data approaching. Everything which can be is being digitalised. It is a perfect storm.
Anders Andrae
Arguably the storm is here already. As the article goes on to point out it’s the cost of keeping increasing amounts of data online, ready to be streamed, that accounts for these observed and forecasted increases.
Just as a thought experiment try to imagine archiving all this data. Imagine some new archiving technology that made it possible to archive it all. Some new decentralized digital vellum that’s orchestrated with smart contracts and runs on cryptocurrency. What impact would archiving all this data have on our environment, and on our planet…to say nothing of our budgets?
This is not to say we don’t need better tech for web archiving–we do. But better web archiving technology won’t save us. We need to be able to think and talk about what we are saving and why. Because we can’t archive it all. In fact, we must not archive it all because that would seriously jeopardize our ability to survive as a species.

The Internet Archive’s mission is to archive the web and to provide universal access to all knowledge (Kahle, 2007). How much of the web is in the Internet Archive? Of course it’s hard, if not impossible, to say. But let’s not let that stop us.
In 2016 Google announced that it had 130 trillion URLs in its index. In a blog post also written in 2016 the Internet Archive shared that they had saved 510 billion web captures. So we could estimate that in 2016 the world’s largest public archive of web content, had collected 0.39% of the web. What 0.39% of the web do you think they archived?
Of course this is mixing apples and oranges, because on the one hand we are talking about web captures and on the other URLs. But comparing distinct URLs in the Internet Archive would only make this percentage smaller. Even worse, Google themselves don’t really know how big the web is: they just know how many distinct URLs their bots have wandered into.
But this low percentage probably doesn’t come as any surprise to the archivists in the room, who know that between 1 and 5 percent of all institutional records will survive as archives (Cook, 2011). As Harris (2007) would perhaps say, the Wayback Machine and all our web archives will always be “a sliver of a sliver of a sliver of a window into process” (Harris, 2007). This is why they are so important to us, and why an environmental analysis is so fundamental to digital preservation work (Goldman, 2018).
We need to decide what to collect. How we decide is what’s important. We need to talk about about how we decided. This is what you do here.
Smaller
Ok, so the web is a lot bigger than us, and trying to archive it all might kill us all, if we were able to do it. But how is web archiving smaller than the IIPC and its individual member institutions?
In August of 2014, my friend and collaborator Bergis Jules and I sat in a bar with a small group of friends at the Society of American Archivists meeting in Washington DC. We were talking about what it would take to collect the tweets about the protests in Ferguson, Missouri that were happening as we spoke.
These protests were in direct response to the murder of African American teenager Mike Brown by police officer Darren Wilson. We were thinking about Zeynep Tufekci’s new piece What Happens in #Ferguson Affects Ferguson about the disparity in what she was seeing in Facebook versus Twitter. We weren’t exactly sure what the right way to do this collection was, but we did know why we wanted to do it. We knew that Ferguson was a significant political and cultural moment that scholars would some day want to study. Forget about the future, we knew researchers would want to study it right now.
So we used a nascent utility called twarc to collect 13 million tweets that contained the word “Ferguson” from August 9 through August 27, 2014. We started writing in a blog about how we were doing the work, and how to use the tweet metadata that had been assembled. We continued doing data collection around the protests of Walter Scott, Freddie Gray, Sandra Bland, Samuel DuBose, Alton Sterling, Philando Castille, Korryn Gaines, and the BlackLivesMatter movement that catalyzed heightened awareness about police violence against people of color, and structural racism. We were emboldened to hear that others wanted to help out, and to do this work too.
Four years and a Mellon grant later we’ve had the opportunity to work together as a team to improve that twarc utility we started with in 2014, and to create a few more tools along the way to help in doing some of this work. These probably don’t seem like your typical web archiving tools, but I’d like you to think about why.
- twarc - a command line tool for collecting tweets from Twitter’s search and streaming APIs, and can collect threaded conversations and user profile information. It also comes with a kitchen sink of utilities contributed by members of the community.
- Catalog - a clearinghouse of Twitter identifier datasets that live in institutional repositories around the web. These have been collected by folks like the University of North Texas, George Washington University, UC Riverside, University of Maryland, York University, Society of Catalan Archivists, University of Virginia, tUniversity of Puerto Rico, North Carolina State University, University of Alberta, Library and Archives Canada, and more.
- Hydrator - A desktop utility for turning tweet identifier datasets (from the Catalog) back into structured JSON and CSV for analysis. It was designed to be able to run for weeks on your laptop, to slowly reassemble a tweet dataset, while respecting Twitter’s Terms of Service, and users right to be forgotten.
- unshrtn - A microservice that makes it possible to bulk normalize and extract metadata from a large number of URLs.
- DiffEngine - a utility that tracks changes on a website using its RSS feed, and publishes these changes to Twitter and Mastodon. As an example see whitehouse_diff which announces changes to the Executive orders made on the White House blog.
- DocNow - An application (still under development) that allows archivists to observe Twitter activity, do data collection, analyze referenced web content, and optionally send it off to the Internet Archive to be archivd.
These tools emerged as part of doing work with social media archives. Rather than building one tool that attempts to solve some of the many problems of archiving social media, we wanted to create small tools that fit particular problems, and could be composed into other people’s projects and workflows. We wanted to thoughtfully intervene into a scholarly communications landscape where researchers were using social media, but not always sharing their methods, and their data sources.
The Ferguson Principles

Truth be told, these tools are actually just a sideshow for what we’ve really been trying to do. Over the past four years we’ve been able to work with an emerging community of archivists, researchers, and activists who already see the value of social media and web archiving, but are interested in developing practices that speak to the ethical concerns that arise when doing this work.
Documenting the Now is a distributed team, with porous boundaries, so having an open Slack channel was useful for coordinating. But the real work happened in several face-to-face meetings in St Louis and Ferguson, Missouri where we heard from activists about how they wanted their social justice work to be remembered. This was only made possible by facilitating direct conversations between archivists, technologists, researchers and activists about how to remember the protests.
These conversations also took place at the Ethics and Archiving the Web conference that was hosted by Rhizome held earlier this year. Drawing on our reading of existing guidelines from the Society of American Archivists and the International Association of Internet Researchers, we developed a set of recommendations described in a white paper, that we have come to informally refer to as the Ferguson Principles. We can discuss in more detail during the Q&A or during a workshop we are holding Friday.
Archivists must engage and work with the communities they wish to document on the web. Archives are often powerful institutions. Attention to the positionality of the archive vis-à-vis content creators, particularly in the case of protest, is a primary consideration that can guide efforts at preservation and access.
Documentation efforts must go beyond what can be collected without permission from the web and social media. Social media collected with the consent of content creators can form a part of richer documentation efforts that include the collection of oral histories, photographs, correspondence, and more. Simply telling the story of what happens in social media is not enough, but it can be a useful start.
Archivists should follow social media platforms’ terms of service only where they are congruent with the values of the communities they are attempting to document. What is legal is not always ethical, and what is ethical is not always legal. Context, agency and (again) positionality matter.
When possible, archivists should apply traditional archival practices such as appraisal, collection development, and donor relations to social media and web materials. It is hard work adapting these concepts to the collection of social media content, but they matter now, more than ever.
These aren’t meant to be global principles to be applied in every situation when you are archiving social media. They are meant to be touchstones for conversations to have, particularly when you are doing web archiving work in the context of social justice.
Now
We recently announced that we received a new round of funding to continue this work, which you can read more about in a post about phase 2. But in a nutshell this funding will allow us to do three interrelated things.
The first is to continue to support and develop the tools we’ve worked on so far. If you’d like to be part of these conversations we will be opening up our technical development calls shortly.
We will also be developing a series of workshops, to help build digital community-based archives in direct partnership with social justice activist organizations. Look for information about how to apply to be part of this in the new year.
And thirdly we will be working with a new project partner, Meredith Clark at the University of Virginia, to develop an openly licensed, college-level curriculum that gives students meaningful experience with, and frameworks for, the ethical use of social media in their research.
So returning to where we started, I’ve been excited to see the IIPC developing its own virtual community in Slack, and that there are efforts such as the Online Hours Supporting Open Source (OH-SOS) and the Training Working Group that allow engagement to grow outside of the select few who are able to attend these yearly face-to-face meetings.
Since I don’t work at an IIPC member institution I’m not totally up on what is going on. But I do think there may be opportunities for the IIPS to adopt some approaches to web archiving tools and practice that get outside of the institutional walls we so often finds ourselves operating in.
I’m specifically thinking of the decades of work by the Australian school, on the Records Continuum model developed by Sue McKemmish, Frank Upward and others (McKemmish, Upward, & Reed, 2010), which takes an expansive and integrative view of what counts as records, and the contexts in which they are produced. Also, strategies drawing on community archiving, where records continue to live in the environments that they were produced could be very generative for moving efforts in this direction (Caswell, Migoni, Geraci, & Cifor, 2016; Flinn, 2007 ; Punzalan, 2009 ). What if we also thought of web archiving work as getting out into the world to help people sustain their websites rather than only taking their content and putting it in a Wayback instance, as what Brügger & Finnemann (2013) calls “reborn digital material”.
So if any of this sounds useful and interesting to you please get in touch with me or Bergis here at IIPC. I believe that Bergis will be around next week at the National Digital Forum as well. As I mentioned we are also hosting a workshop Friday morning in which we are going to be exploring some of the Ferguson Principles and more in a group setting. And finally please consider joining our Slack, asking questions, and joining the conversation there.
Thanks!
References
Brügger, N., & Finnemann, N. O. (2013). The web and digital humanities: Theoretical and methodological concerns. Journal of Broadcasting & Electronic Media, 57(1), 66–80. Retrieved from http://search.ebscohost.com.proxy-um.researchport.umd.edu/login.aspx?direct=true&db=a9h&AN=86010172&site=ehost-live
Caswell, M., Migoni, A. A., Geraci, N., & Cifor, M. (2016). “To be able to imagine otherwise”: Community archives and the importance of representation. Archives and Records. Retrieved from http://www.tandfonline.com/doi/full/10.1080/23257962.2016.1260445
Cook, T. (2011). We are what we keep; we keep what we are: Archival appraisal past, present and future. Journal of the Society of Archivists, 32(2), 173–189.
Flinn, A. (2007). Community histories, community archives: Some opportunities and challenges 1. Journal of the Society of Archivists, 28(2), 151–176.
Goldman, B. (2018). It’s not easy being green(e): Digital preservation in the age of climate change. In Archival values: Essays in honor of Mark Greene. Society of American Archivists. Retrieved from https://scholarsphere.psu.edu/concern/generic_works/bvq27zn11p
Harris, V. (2007). Society of american archivists. In (pp. 101–106).
Kahle, B. (2007). Universal access to all knowledge. The American Archivist, 70(1), 23–31.
Lave, J., & Wenger, E. (1991). Situated learning: Legitimate peripheral participation. Cambridge Ueniversity Press.
McKemmish, S., Upward, F., & Reed, B. (2010). Records continuum model. In M. Bates & M. N. Maack (Eds.), Encyclopedia of library and information sciences. Taylor & Francis.
Punzalan, R. L. (2009). ’All the things we cannot articulate’: Colonial leprosy archives and community commemoration. In J. A. Bastian & B. Alexander (Eds.), Community archives: The shaping of memory. Facet Publishing.
ahumblecabbage:I don’t trust reddit because it’s the only social network whose users don’t hate the...
Stephen LaPorteI can trust my love for The Old Reader because I very much wanted to write them an angry email about their dark mode CSS.
I don’t trust reddit because it’s the only social network whose users don’t hate the website they’re using. twitter users hate twitter. snapchat users hate snapchat. but reddit users will get a neck tattoo of the goofy little alien friend and name their first born son r/gaming
ARL, Wikimedia, and Linked Open Data: Draft White Paper Open for Comments through November 30 | Association of Research Libraries® | ARL®
Stephen LaPorteIdeas for Wikicite.
Untitled (https://www.youtube.com/watch?v=ajGX7odA87k)
Stephen LaPorteSo good
Saturday Morning Breakfast Cereal - Literary Turing
Stephen LaPorteI think this is basically everything great and everything wrong with Twitter's relationship with the news, too.
.png)
Click here to go see the bonus panel!
Hovertext:
Thanks to Ken, Michael, and Barbara from patreon for helping make this more clear! If anything is confusing, it's their fault.
Today's News:
What Does the Path to Fame Look Like?
Ploughman's lunch - Wikipedia, the free encyclopedia
Stephen LaPorteBen's ancestral food, doesn't sound too bad
ultrafacts: Source: [x] Follow Ultrafacts for more facts!
Stephen LaPorteYou drove me to make my most disappointing edit to Wikipedia: https://en.wikipedia.org/w/index.php?title=Uraba_lugens&diff=857035250&oldid=856669664

ambergrief:
Stephen LaPorteGlad he survived. (BTW, that's probably a 4 on the Schmidt sting pain index.)
Stephen LaPorteThe trailer is very similar to Journey. Slightly less lonesome, maybe. Nothing wrong with borrowing for inspiration, but that's treated oddly in the interview.
Photo
Stephen LaPorteI was hoping we'd have a new "government sponsored" disclaimer on knowyourmeme, but fortunately (unfortunately?) these paragraphs aren't in the real indictment.

How Much Money Do You Need to Be Happy? A New Study Gives Us Some Exact Figures

“If I gave you a million dollars, would you…?” (insert possibly life-altering risk, humiliation, or soul-selling crime here). What about ten million? 100 million? One BILLION dollars? Put another way, in the terms social scientists use these days, how much money is enough to make you happy?
If you’re Montgomery Burns, it’s at least a billion dollars, lest you be forced to suffer the torments of the Millionaire’s Camp. (“Just kill me now!”) As it tends to do, The Simpsons’ dark humor nails the insatiable greed that seems the scourge of our time, when the richest 1 percent take 82 percent of the world’s wealth, and the poorest 50 percent get nothing at all.
Hypothetical windfalls aside, the question of how much is enough is an urgent one for many people: as in, how much to feed a family, supply life’s necessities, purchase just enough leisure for some small degree of personal fulfilment?
As the misery of Monty Burns demonstrates, we have a sense of the 1% as eternally unfulfilled. He’s the wicked heir to more serious tragic figures like Charles Foster Kane and Jay Gatsby. But satire is one thing, and desire, that linchpin of the economy, is another.
“What we see on TV and what advertisers tell us we need would indicate there is no ceiling when it comes to how much money is needed for happiness,” says Purdue University psychologist Andrew T. Jebb, “but we now see there are some thresholds.” In short: money is a good thing, but there is such a thing as too much of it.
Jebb and his colleagues from Purdue and the University of Virginia addressed questions in their study “Happiness, income satiation and turning points around the world” like, “Does happiness rise indefinitely with income, or is there a point at which higher incomes no longer lead to greater wellbeing?” What they found in data from an international Gallup World Poll survey of over 1.7 million people in 164 countries varies widely across the world.
People in wealthier areas seem to require more income for happiness (or “Subjective Well Being” in the social science terminology). In many parts of the world, higher incomes, “beyond satiation”—a metric that measures how much is enough—“are associated with lower life evaluations.” The authors also note that "a recent study at the country level found a slight but significant decline in life evaluation" among very high earners "in the richest countries."
You can see the wide variance in happiness worldwide in the “Happiness” study. As Dan Kopf notes at Quartz, these research findings are consistent with those of other researchers of happiness and income, though they go into much more detail. Problems with the methodology of these studies—primarily their reliance on self-reported data—make them vulnerable to several critiques.
But, assuming they demonstrate real quantities, what, on average, do they tell us? “We found that the ideal income point," averaged out in U.S. dollars, "is $95,000 for [overall life satisfaction],” says Jebb, “and $60,000 to $75,000 for emotional well-being,” a measure of day-to-day happiness. These are, mind you, individual incomes and “would likely be higher for families,” he says.
Peter Dockrill at Science Alert summarizes some other interesting findings: “Globally, it’s cheaper for men to be satisfied with their lives ($90,000) than women ($100,000), and for people of low ($70,000) or moderate education ($85,000) than people with higher education ($115,000).”
Yes, the study, like those before it, shows that after the “satiation point,” happiness decreases, though perhaps not to Monty Burns levels of dissatisfaction. But where does this leave most of us in the new Gilded Age? Given that "satiation" in the U.S. is around $105K, with day-to-day happiness around $85K, the majority of Americans fall well below the happiness line. The median salary for U.S. workers at the end of 2017 was $44, 564, according to the Bureau of Labor Statistics. Managers and professionals averaged $64,220 and service workers around $28,000. (As you might imagine, income inequality diverged sharply along racial lines.)
And while the middle class saw a slight bump in income in the last couple years, median household income was still only $59,039 in 2016. However, we measure it the "middle class... has been declining for four decades,” admits Business Insider—“identifying with the middle class is, in part, a state of mind” rather than a state of debt-to-income ratios. (One study shows that Millennials make 20% less than Baby Boomers did at the same age.) Meanwhile, as wealth increases at the top, “the country’s bottom 20% of earners became worse off.”
This may all sound like bad news for the happiness quotient of the majority, if happiness (or Subjective Well Being) requires a certain amount of material security. Maybe one positive takeaway is that it doesn’t require nearly the amount of vast private wealth that has accumulated in the hands of a very few people. According to this research, significantly redistributing that wealth might actually make the wealthy a little happier, and less Mr. Burns-like, even as it raised happiness standards a great deal for millions of others.
Not only are higher incomes "usually accompanied by higher demands," as Jebb and his colleagues conclude—on one's time, and perhaps on one's conscience—but "additional factors" may also play a role in decreasing happiness as incomes rise, including "an increase in materialistic values, additional material aspirations that may go unfulfilled, increased social comparisons," etc. The longstanding truism about money not buying love—or fulfillment, meaning, peace of mind, what-have-you—may well just be true.
You can dig further into Andrew T. Jebb's study here: “Happiness, income satiation and turning points around the world.”
Related Content:
Josh Jones is a writer and musician based in Durham, NC. Follow him at @jdmagness
How Much Money Do You Need to Be Happy? A New Study Gives Us Some Exact Figures is a post from: Open Culture. Follow us on Facebook, Twitter, and Google Plus, or get our Daily Email. And don't miss our big collections of Free Online Courses, Free Online Movies, Free eBooks, Free Audio Books, Free Foreign Language Lessons, and MOOCs.